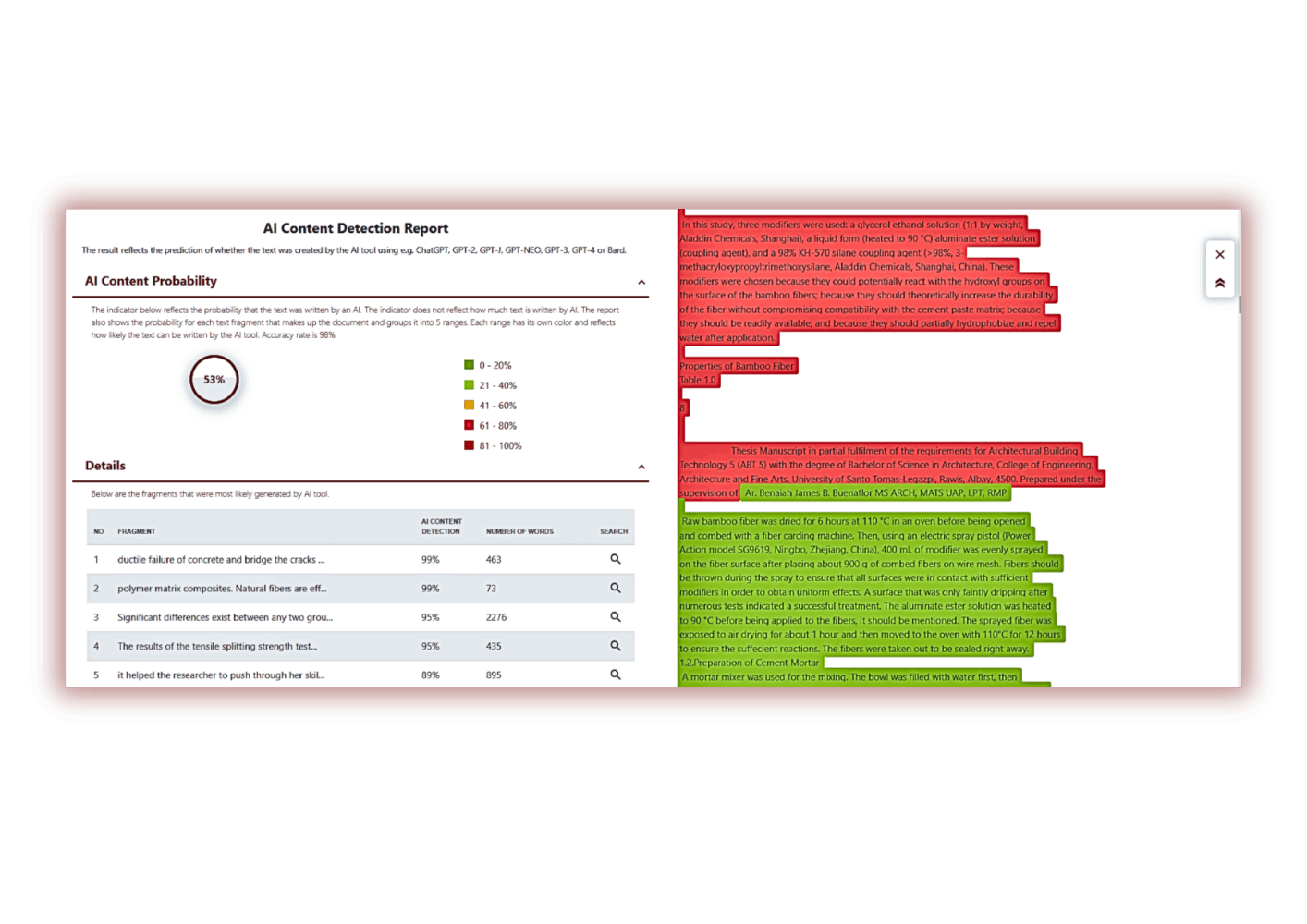
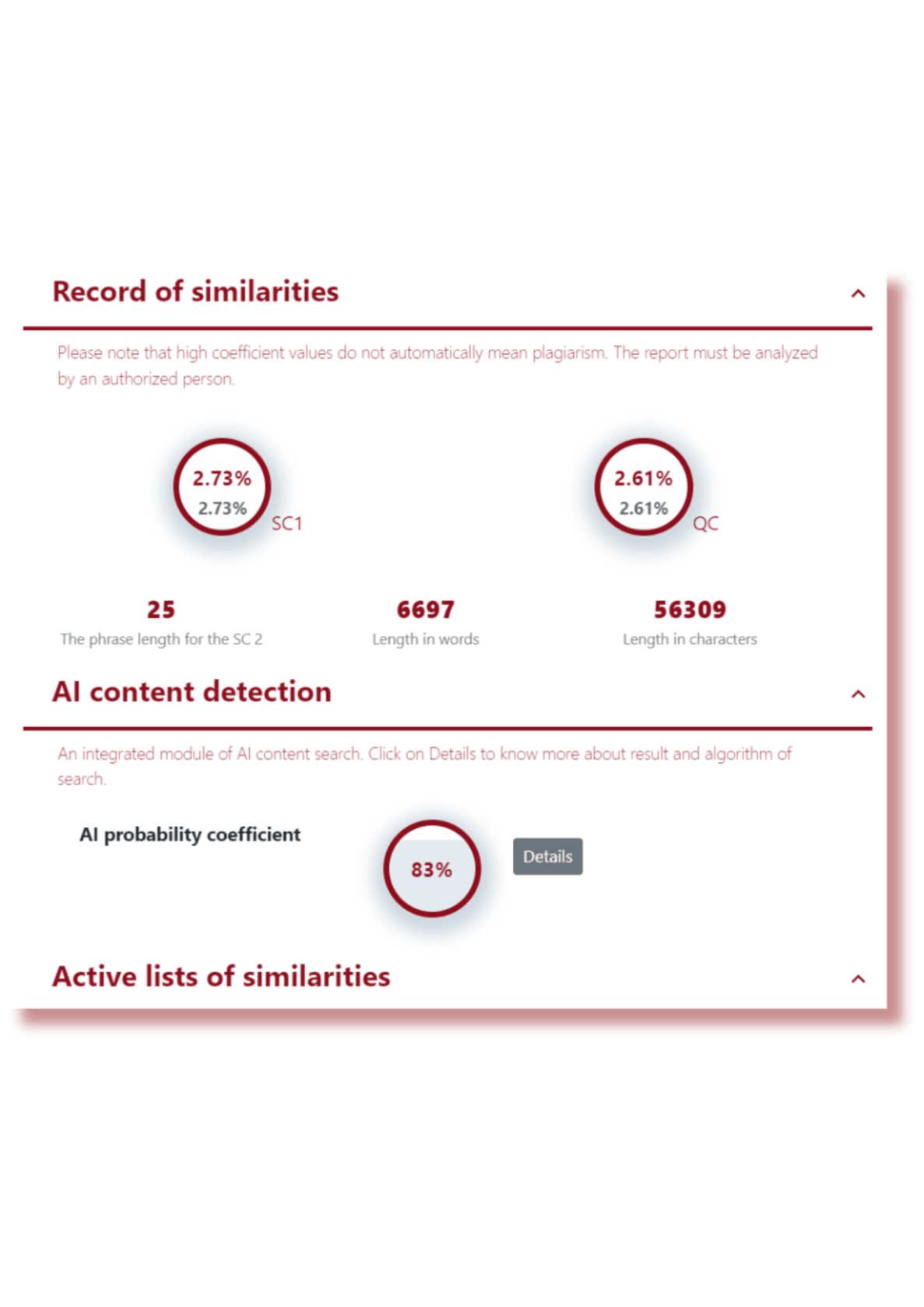
AI content search module
We have noticed that students and educators are actively using various mechanisms and tools for content creation, including AI tools.
AI tools have become part of the educational process, although they have only recently appeared. Students and teachers are using them because they are very efficient, fast and have access to significant amounts of information. However, there is some risk associated with the use of AI tools.