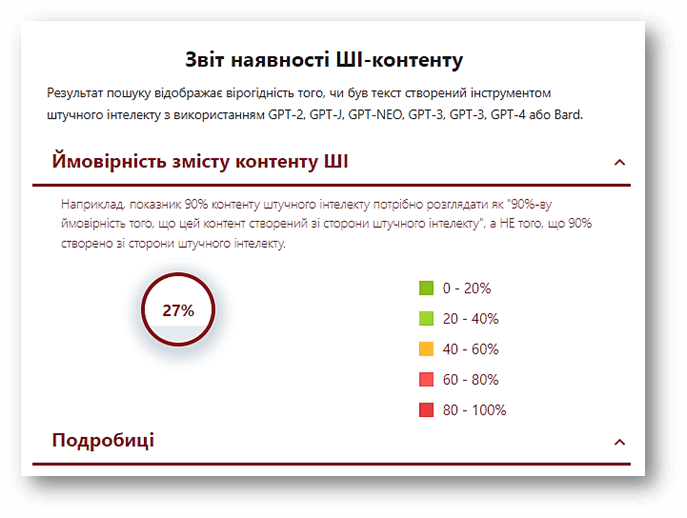
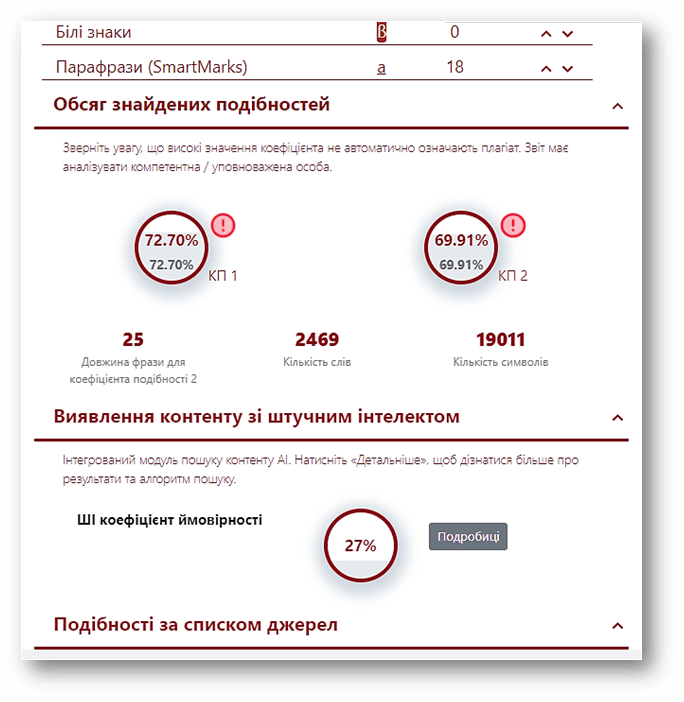
Модуль пошуку контенту штучного інтелекту
Ми помітили, що в університетах збільшились випадки використання різних механізмів і інструментів створення контенту, в тому числі ChatGPT, Bard.
Інструменти ШІ стали частиною навчального процесу, хоча й з'явились зовсім недавно. Студенти та викладачі почали активно їх використовувати, через те, що вони дуже ефективні, швидкі і мають доступ до значних об'ємів інформації. Але, при написанні, як наукової роботи, так і студентської повинна існувати певна розумна межа використання ШІ, тобто межа зловживання.