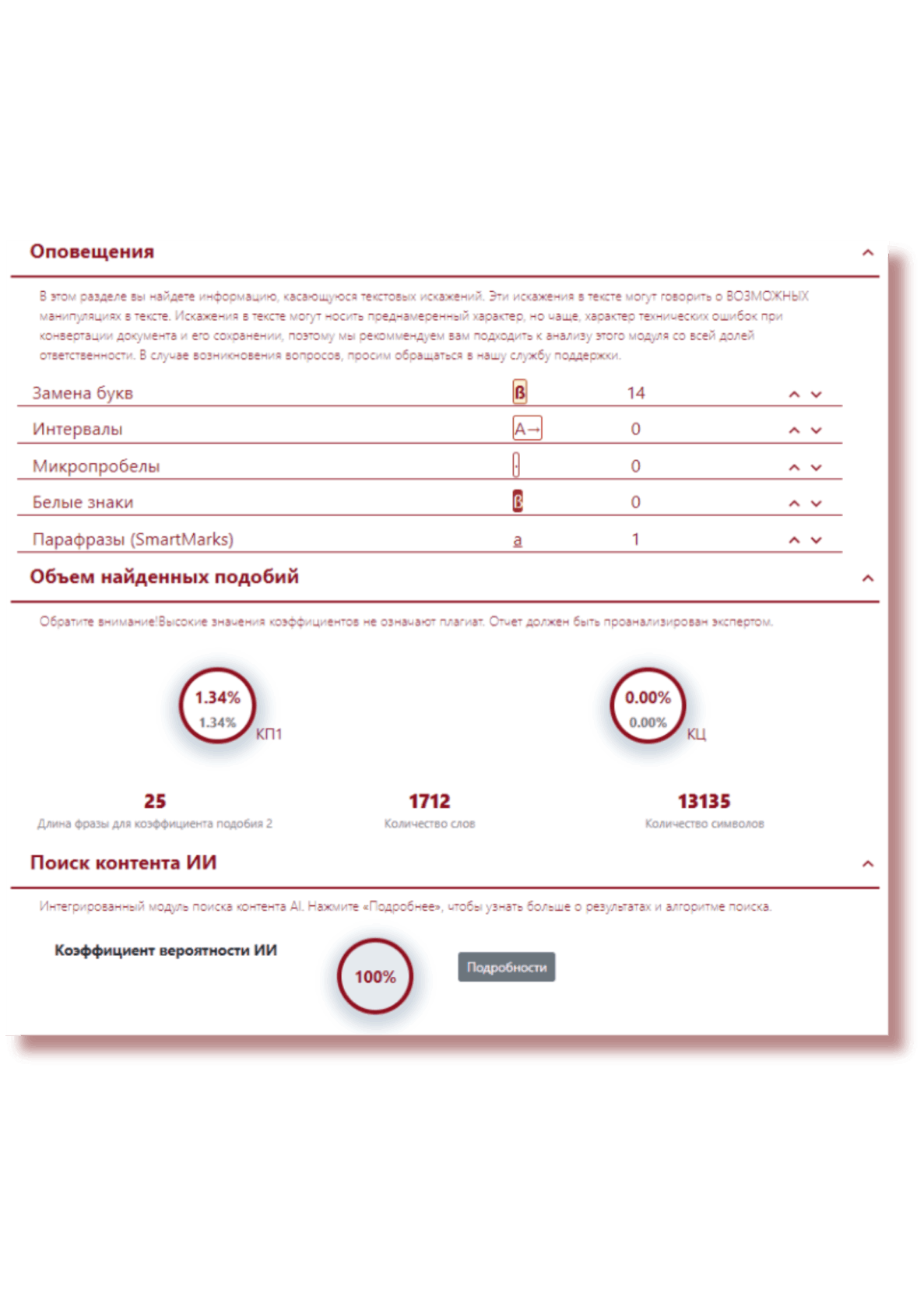
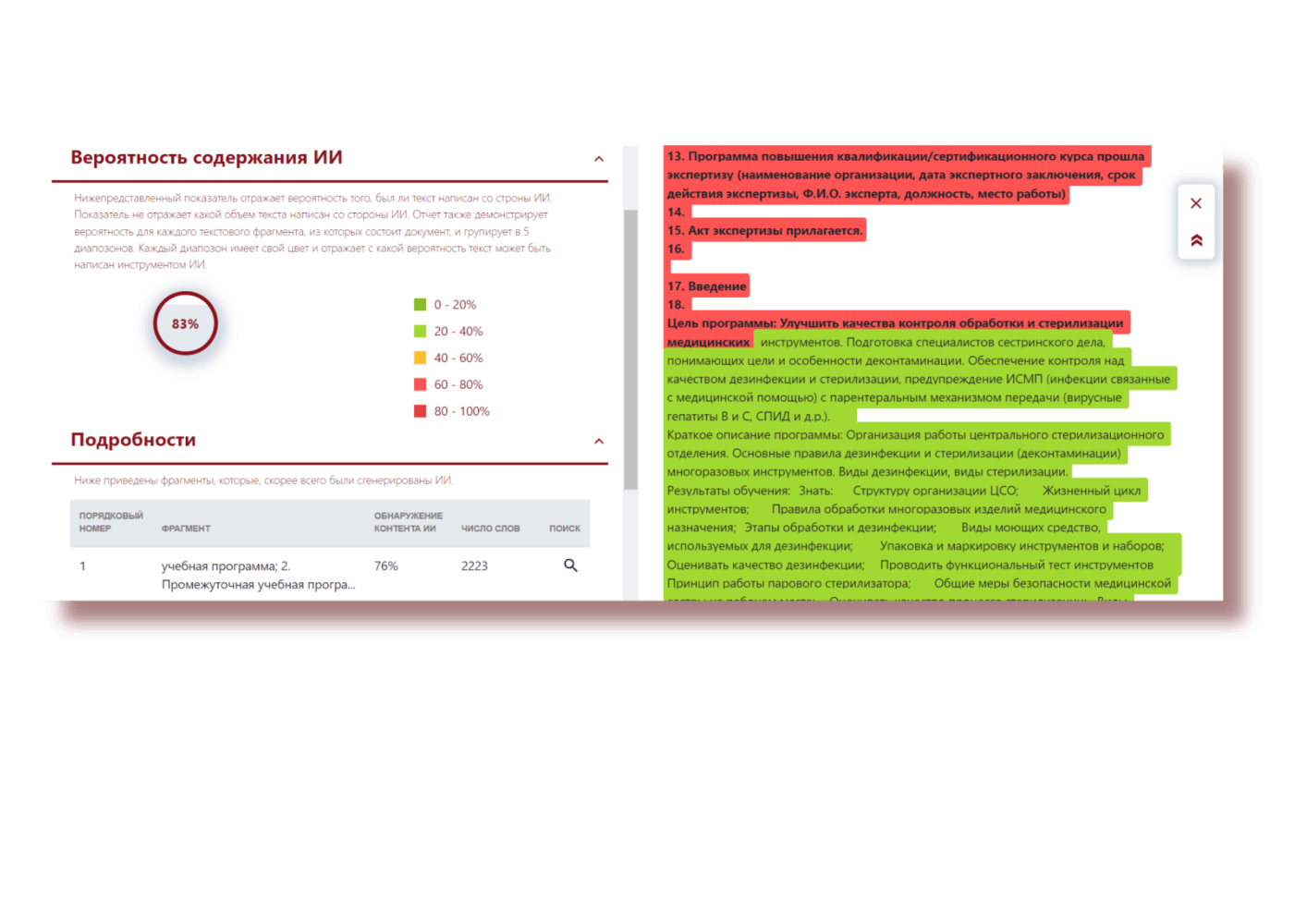
Модуль поиска контента искусственного интеллекта
Мы заметили, что в университетах участились случаи использования различных механизмов и инструментов создания контента, в том числе ChatGPT, Bard.
Инструменты ИИ стали частью образовательного процесса, хотя появились совсем недавно. Студенты и преподаватели начали активно их использовать, так как они очень эффективны, быстры и имеют доступ к значительным объемам информации. Однако, как при написании научной работы, так и студенческой работы должна быть какая-то граница разумного использования ИИ, то есть граница злаупотребления.