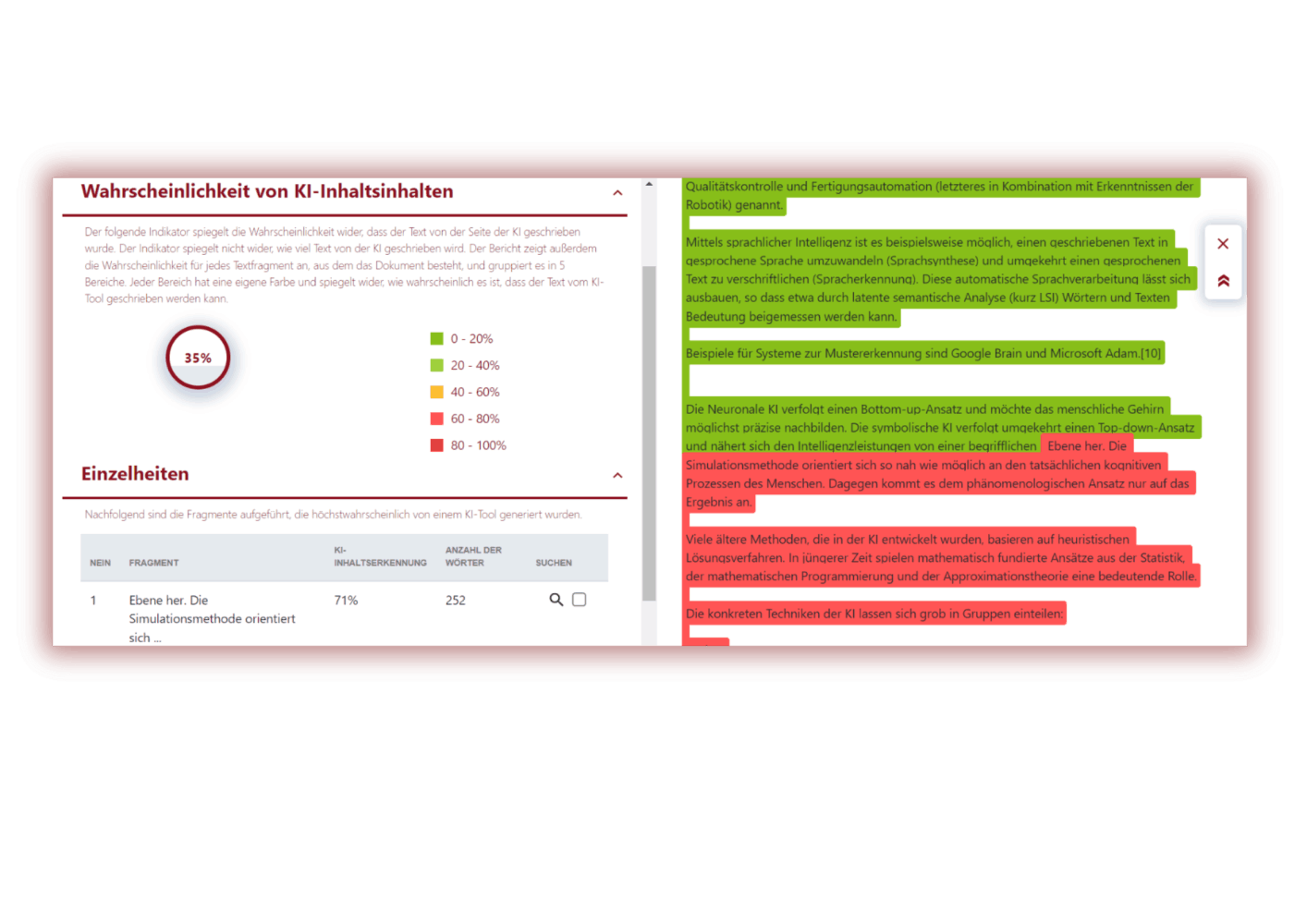
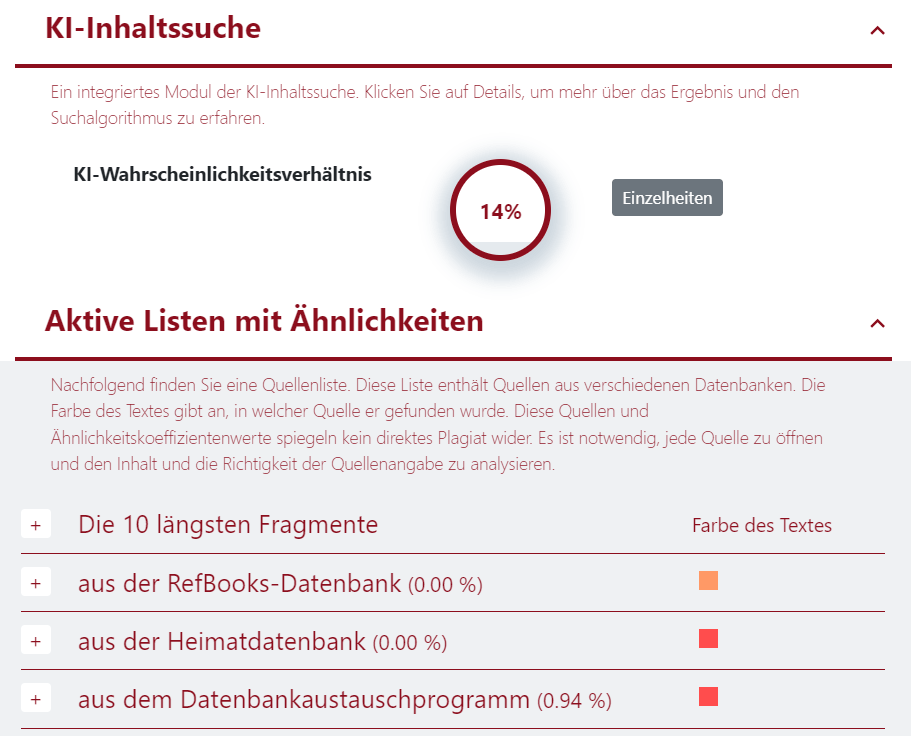
Modul für die Suche nach KI-Inhalten
Wir haben festgestellt, dass Studierende und Lehrkräfte aktiv verschiedene Mechanismen und Werkzeuge für die Erstellung von Inhalten nutzen, darunter auch KI-Tools.
KI-Tools sind Teil des Bildungsprozesses geworden, obwohl sie erst vor kurzem erschienen sind. Schüler und Lehrer nutzen sie, weil sie sehr effizient und schnell sind und Zugang zu großen Informationsmengen haben. Allerdings birgt der Einsatz von KI-Tools auch einige Risiken.